
Developing Agents — Rethinking with Modern Models

This essay was originally cross-posted on LinkedIn as part of my ongoing reflections on AI agents and reasoning systems.
Last week, I shared a LinkedIn post about Rippling’s partnership with OpenAI on Agent Builder and the proof-of-concept our team built to explore how Rippling’s workforce data could power smarter AI agents.
That experiment and the conversations it sparked internally about OpenAI Agent Builder, LangChain ‘s LangGraph along with Harrison Chase ’s blog “Not Another Workflow Builder” connected a few dots for me. They mirror what we’ve been learning at Rippling as we move from deterministic agents to what I now think of as deep agents: systems that reason, adapt, and self-correct.
In enterprise B2B SaaS products, where everything has traditionally been deterministic, I’ve spent the first half of this year pushing for precision i.e. workflows that always do the right thing, the same way. But the recent work by our Applied ML team — Emerson Matson, Amit Butala , Julien Kernech , Senthil Velu Sundaram , Akash Ashok , Karthik Harihar Reddy , Bryant Chen , Neerav Kharche and Yi Song made me realize just how much LLMs have evolved, and how deeply that evolution changes how we think about agents.
It crystallized something deeper for me: the very foundation of how large models have evolved over the last three years and how that changes everything about how we build agents.
From Prediction to Perception
We learned that LLMs are prediction engines — trained on the internet, predicting the next token. With larger and larger datasets, they learned our language and, in a way, our world’s knowledge.
They were essentially statistical mirrors i.e. able to reproduce, but not to reason about meaning or consequence. All this pre-training on ever-larger corpora created competence and models that could answer almost any question we asked.
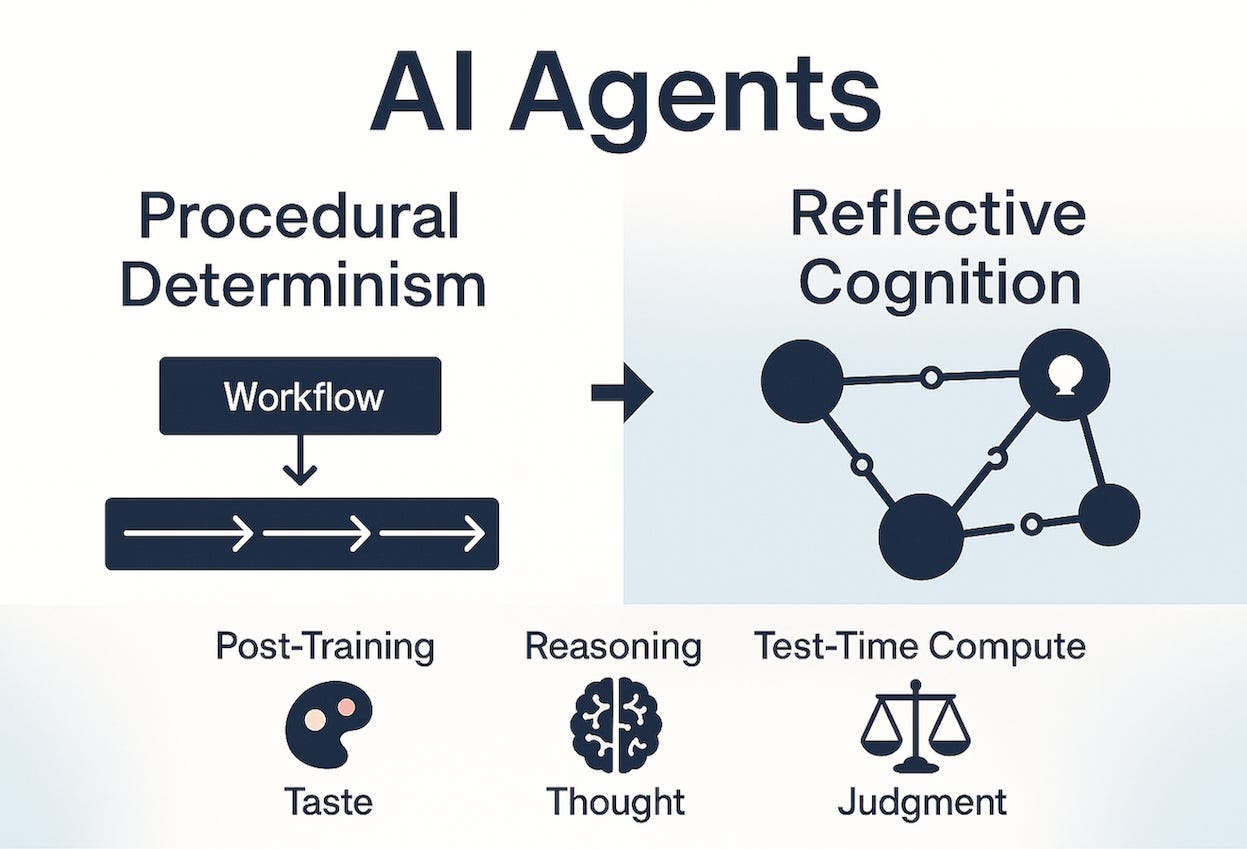
But everyone complained about taste and accuracy. That’s where researchers pushed the boundaries and added three key innovations that now define modern frontier models:
Post-Training
Reasoning Models
Test-Time Compute
Post-training gave models taste. Reasoning models gave them depth of thought. Test-time compute gave them judgment, the ability to decide when to think harder.
Let’s explore each one more closely, how they changed not just what models say, but how they think.
Post-Training — Teaching Models Taste
The first real leap came when researchers realized that, for all their fluency, models still didn’t know what good looked like. So they began showing them.
Post-training sits between pre-training and deployment essentially the step where a model that can speak learns to speak well. Early work such as FLAN (Wei et al., 2022) and InstructGPT (Ouyang et al., 2022) fine-tuned large models on thousands of examples of helpful, well-structured responses so that they followed intent instead of merely completing text. Next came Reinforcement Learning from Human Feedback (Christiano et al., 2020), which added human comparison as a reward signal, and Direct Preference Optimization (Rafailov et al., 2023), which simplified that loop into clean math. Anthropic’s Constitutional AI (Bai et al., 2022) went one step further by letting the model self-critique against written principles instead of relying on endless human raters.
Each of these layers nudged models toward discernment: clarity over confusion, safety over shock value, usefulness over noise. In short, post-training gave models taste and a sense of what “better” feels like.
Reasoning Models — Teaching Models to Think
Once models developed taste, the next question was obvious: could they think? Researchers noticed that when prompted to “think step-by-step,” models produced more accurate answers. It wasn’t new data or parameters; it was permission to reason out loud.
That insight evolved into reasoning-centric post-training i.e. rewarding not just answers but the process of reaching them. Modern systems such as OpenAI o1/o3 and DeepSeek-R1 (DeepSeek Team, 2025) use reasoning RL, a reinforcement objective that grades the quality of reasoning traces. The model isn’t just right or wrong; it’s evaluated on whether its logic holds together.
Think of teaching math: you don’t only check the final number but you examine the steps. Reasoning models follow that same rule. They are rewarded for showing their work and for thinking in public.
The comprehensive Survey on Post-Training of LLMs (Tie et al., 2025) unites all these methods — SFT, RLHF, AI feedback, self-play, reasoning-RL into one continuum. If post-training taught models what good feels like, reasoning training taught them why it’s good.
Test-Time Compute — Teaching Models Judgment
Once models could reason, a new challenge appeared: how long should they think before answering? That’s what test-time compute addresses, letting a model decide dynamically how much mental effort a question deserves.
Earlier models replied instantly in one pass. Modern reasoning systems such as GPT-5 or DeepSeek-R1 can branch internally, explore multiple solution paths, self-evaluate, and then choose the best one. They “pause” when the problem is hard and move faster when it’s easy.
Research like Scaling LLM Test-Time Compute Optimally (Snell et al., ICLR 2025), Forest-of-Thought (Yao et al., 2024), and Sleep-Time Compute (2025) formalized this idea, showing that extra inference steps can outperform simply scaling model size.
In plain terms:
Pre-training taught models to know. Post-training taught them to care. Test-time compute teaches them to pause and reflect.
That ability to spend effort wisely and to reason longer when it matters is what we now call judgment. It’s not only how smart a model is, but when it chooses to use that intelligence.
The Integration — Thinking, Judging, Adapting
By 2025, these three layers began to converge. Frontier systems such as GPT-5, Claude 3, and Gemini 2 now blend alignment (post-training), reasoning (multi-step thought), and reflection (adaptive compute).
The latest research describes this convergence as a reasoning economy which is ultimately a balance between what a model has learned, how it reasons, and how much compute it spends per problem. Works like Harnessing the Reasoning Economy (2025) and A Survey of Slow-Thinking LLMs via RL (2025) call this formal “slow thinking,” borrowing the term from Daniel Kahneman.
The insight is simple but profound:
Intelligence isn’t just what you know or how fast you reply but knowing when to slow down and think.
That’s exactly what these new reasoning models do. They’ve evolved from prediction to perception, from recall to reflection. They no longer mirror our text but they model our judgment.
Why It Matters
This progression matters because it directly changes how we build AI agents. Every modern model we use today : GPT-5, Claude 3, Gemini 2 are already post-trained, reasoning-aligned, and compute-adaptive. They’re not neutral archives of text; they’re systems trained on preference, reflection, and reasoning.
These models have been exposed to millions of comparisons and critiques that define what counts as helpful, truthful, and safe. They no longer speak the world’s text but they echo the world’s judgments.
That shift has completely reframed how I think about agent design. In enterprise environments like Rippling, we used to design deterministic agentic workflows that are tightly controlled systems that always behaved the same way. But the next generation of deep agents will behave differently. They won’t just execute steps; they’ll reason through them. They’ll decide when to escalate, when to ask for context, and when to act.
At Rippling, we’ve already started applying these principles in practice. Our latest work with LangChain 1.0 and LangGraph reflects this shift in design. We rely heavily on LangGraph’s durable runtime to power our agent developments, which now orchestrate reasoning and tool usage more adaptively. With the new agent prebuilt and middleware in LangChain 1.0, the framework is significantly more flexible and composable. It’s a great example of how the ecosystem itself is evolving from deterministic workflows to deep, reasoning-driven agents.
Recent research is reinforcing this direction. In Agentic Context Engineering (ACE), Zhang et al. (Stanford + SambaNova, 2025) introduce a framework that treats an agent’s context as a living playbook that evolves through generation, reflection, and curation. Rather than rewriting prompts or retraining models, ACE incrementally refines the context itself, preserving domain insights and preventing what the authors call context collapse. Their results are striking: ACE improves agent performance by +10.6 % on the AppWorld benchmark while cutting adaptation latency by 86.9 %. The principle is simple but powerful where instead of compressing context, let it grow and self-organize, much like how reasoning models refine their own internal state.
This direction complements the broader shift I describe here: from static workflows to self-evolving agents. That’s a profound shift from procedural determinism to reflective cognition.
Closing Thought
We began by teaching models to speak. Then to care. Now we’re teaching them to pause and think.
Agents functioning as workflows could automate, but they couldn’t interpret. We gained precision but lost perception. Thats the same gap pre-training once had before post-training brought judgment to models. That same judgment now needs to be added to agents:
Agent development is no longer about delegating through fixed intent maps. We can give a single reasoning model a toolbox and let it decide.
This is the shift from automation to orchestration, from workflows that follow instructions to agents that understand intent. That’s not just better AI, that’s beginning of judgment.
(c) 2025 Ankur Bhatt — reflections on AI and the evolution of reasoning models.