
Agentic Engineering: Why the Harness Matters More Than the Model
The coding agent on our laptops and the agent we ship to production share the same architecture. The same loop. The same failure modes. Once we see that, it changes how we think about all of it.

The Equation
We are all using agents today. Claude Code, Cursor, Codex. Some of us use all three before lunch. And we build them. Products that serve our customers every day.
The coding agent on our laptops and the agent we ship to production share the same architecture. The same loop. The same primitives. The same failure modes. Once we see that, it changes how we think about all of it.
The noise right now is real. Skills, hooks, harnesses, sub-agents, AGENTS.md, CLAUDE.md, context engineering. The vocabulary doubles every quarter. And in the middle of all that vocabulary, two failure modes keep showing up.
The first is the plateau. An engineer finds a workflow. It works. They are productive. But they stop getting better. The tools evolved and they did not evolve with them.
The second is the treadmill. An engineer adopts everything. Every MCP server, every new skill format, every plugin. And the output does not improve. Sometimes it gets worse. More tools, worse results. Both patterns come from the same root cause.
We are thinking about agents as chat interfaces with better autocomplete.
We are not thinking about them as systems.
The fact of the matter is: there is one loop, one set of primitives. Understand them, and the noise turns into signal. We can evaluate any new tool in thirty seconds. We can debug any agent failure in minutes, not hours. The engineers who get this are shipping in hours what their peers are shipping in weeks.
Not a marginal gain. A step-function.
The research is starting to confirm what builders have been feeling. UC Berkeley’s MAST taxonomy analyzed over 1,600 agent execution traces across seven frameworks and found that the majority of failures trace to specification and system design, not model limitations. Google DeepMind ran 180 controlled configurations and found that adding more agents actually degrades performance by 39 to 70 percent on sequential reasoning tasks. And in March 2026, when Anthropic accidentally shipped Claude Code’s full TypeScript source in a .map file, the community’s central takeaway was not about the model. It was about the harness. 512,000 lines of orchestration. A radically simple while(tool_call) loop. The conclusion, in their words: “Building reliable AI agents is primarily an orchestration engineering problem, not a model capability problem.”
LangChain proved this quantitatively. They kept the model fixed at GPT-5.2-Codex, changed only the harness, and improved from 52.8% to 66.5% on Terminal Bench 2.0. Same model. Better harness. Top 30 to Top 5.
The variable that matters is not the model. It is everything around the model. Wei et al.’s comprehensive survey of agentic reasoning arrives at the same decomposition from control theory: they factorize the agent policy into an internal reasoning component and an external execution component. Model and harness. The academic literature and the production evidence converge on the same equation.
Agent = Model + Harness.
The model is the reasoning engine. It thinks, plans, decides. The harness is the execution engine. It acts on behalf of the model. It calls tools, reads configurations, manages memory, runs verification. The model gives instructions to the harness. The harness takes action. The model observes what happened. Then it reasons again. That loop is the entire architecture. Everything else is detail.
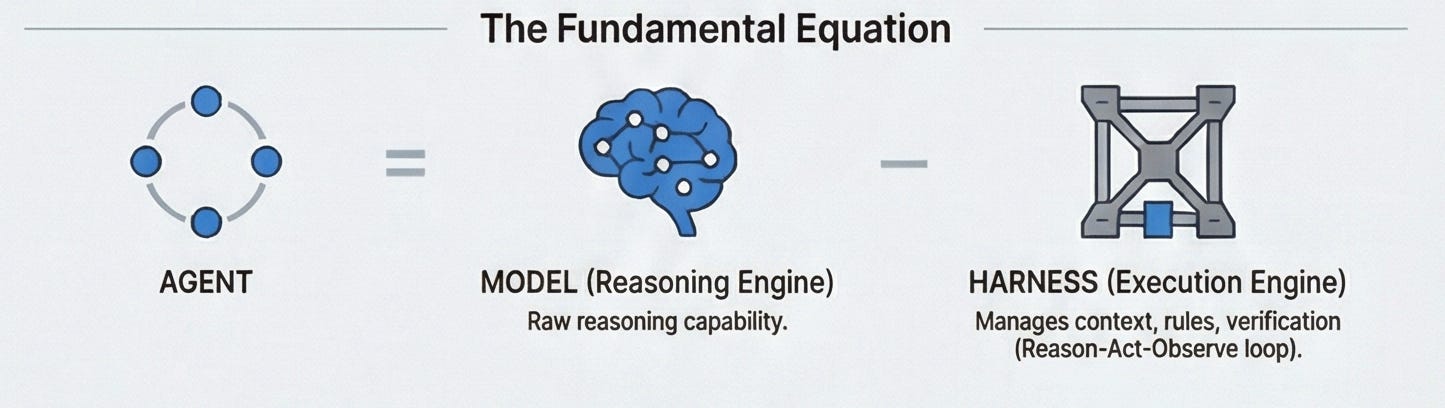
Simon Willison, in his Agentic Engineering Patterns guide, arrived at the same framing independently: “A coding agent is a piece of software that acts as a harness for an LLM, extending that LLM with additional capabilities that are powered by invisible prompts and implemented as callable tools.” Harrison Chase calls the harness “every piece of code, configuration, and execution logic that is not the model itself.” Karpathy puts it differently: the LLM is the CPU, the context window is RAM.
Now if you think about what that means, harness engineering is essentially operating system design. And most of us are running our agents on bare metal with no OS.
The metaphor we keep coming back to is the new-hire intern. We give them a goal. We give them context. We give them tasks. They iterate. That is essentially how an agent operates. The intern is not incapable. They can be remarkably good. But their output depends almost entirely on the quality of the onboarding, the clarity of the goal, and the feedback loops we put in place. Same intern, different onboarding, completely different outcome. Same model, different harness, completely different outcome.
Model contains the intelligence.
Harness makes it usable.
We have explored previously how model labs are becoming agent labs, how trust frameworks earn agent autonomy, and how sensemaking gives agents decision memory. Those articles address the organizational and architectural layers. This article addresses something more immediate. We are all in the loop every day. The question is whether we understand the loop well enough to get the outcomes we actually want.
The answer is not a better prompt. It is not a bigger model. It is a better harness. And the discipline of building better harnesses is what I call agentic engineering.
Six principles follow. They apply whether we are building a product agent or using a coding agent to ship software. Same equation. Same loop. Same primitives. The skills that made us great at software engineering are the skills that make us great at this. Systems thinking. Architecture. Decomposition. Taste. Not less relevant. More.
The Loop
The architecture has a name. Yao et al. introduced it in 2022 as ReAct: Reason, Act, Observe. The model reasons about what to do next. It sends an instruction to the harness. The harness executes. The model observes the result. Then it reasons again.
A chatbot does this once. We ask, it answers. An agent does it five, ten, twenty times. Self-directed. Each cycle produces new information that feeds the next cycle. The loop runs until the task is done or the agent decides it has nothing left to do.
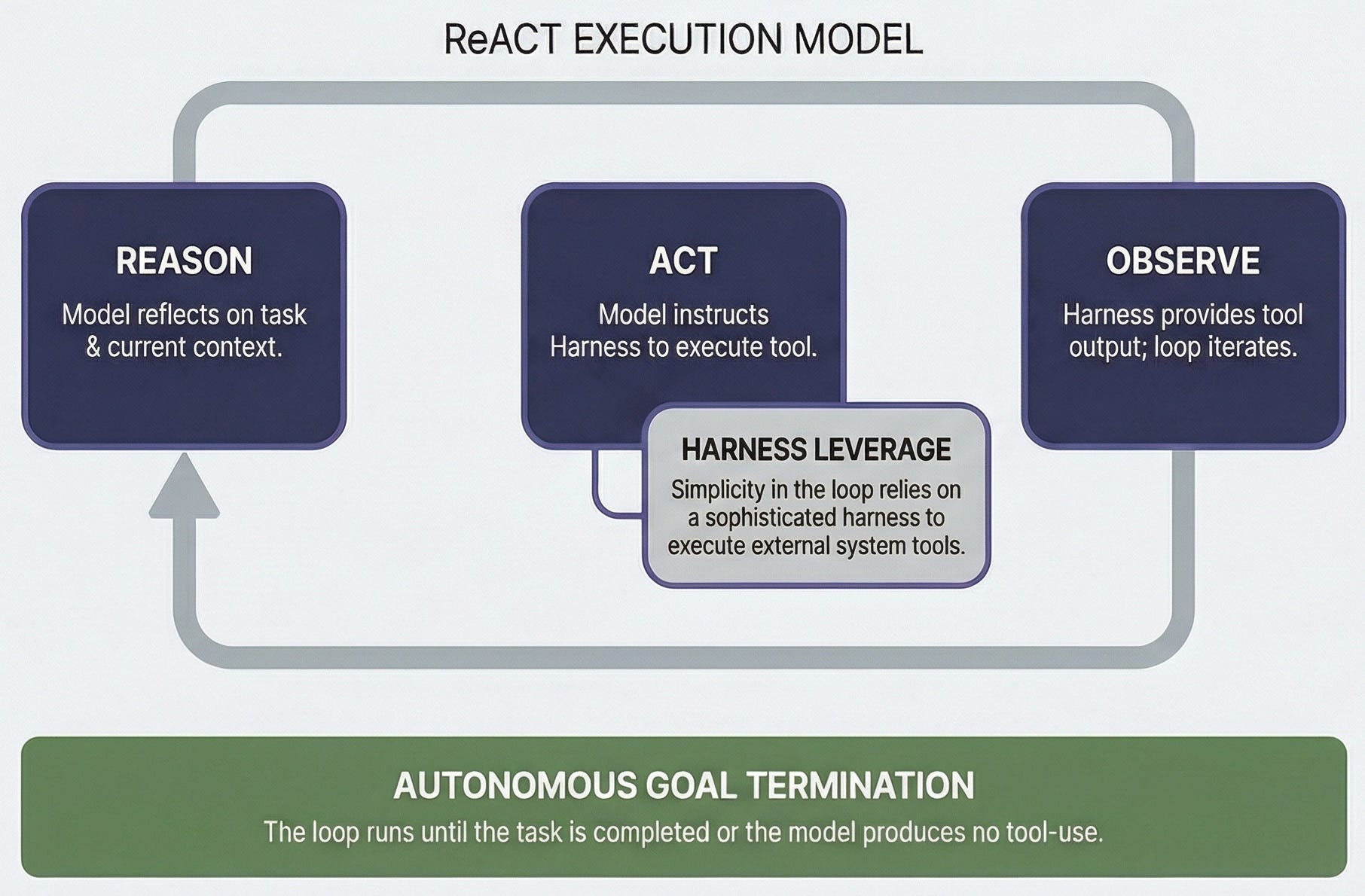
That is the entire execution model. Let us see what it looks like.
Take a simple task: add input validation to a signup form.
We type the task into Claude Code or Cursor. Here is what happens underneath.
Cycle one. The model reasons: “I need to understand this form.” It tells the harness to read
signup.tsx. The harness reads the file, returns the content. The model observes: four fields, no validation.Cycle two. The model reasons: “Are there existing validation patterns?” It tells the harness to search the codebase. The harness runs a grep. The model observes: there is a validation.ts with helpers.
Cycle three. Check the tests. Only happy-path coverage.
Cycle four. Implement validation using the existing patterns, write edge-case tests. Twelve tests pass. Cycle five. Run the build. Succeeds.
Five cycles. Five decisions. The model reasoned. The harness executed. At no point did we tell the agent which file to read first or which search to run. The agent navigated through the loop, making one decision per cycle, observing the result, adjusting.
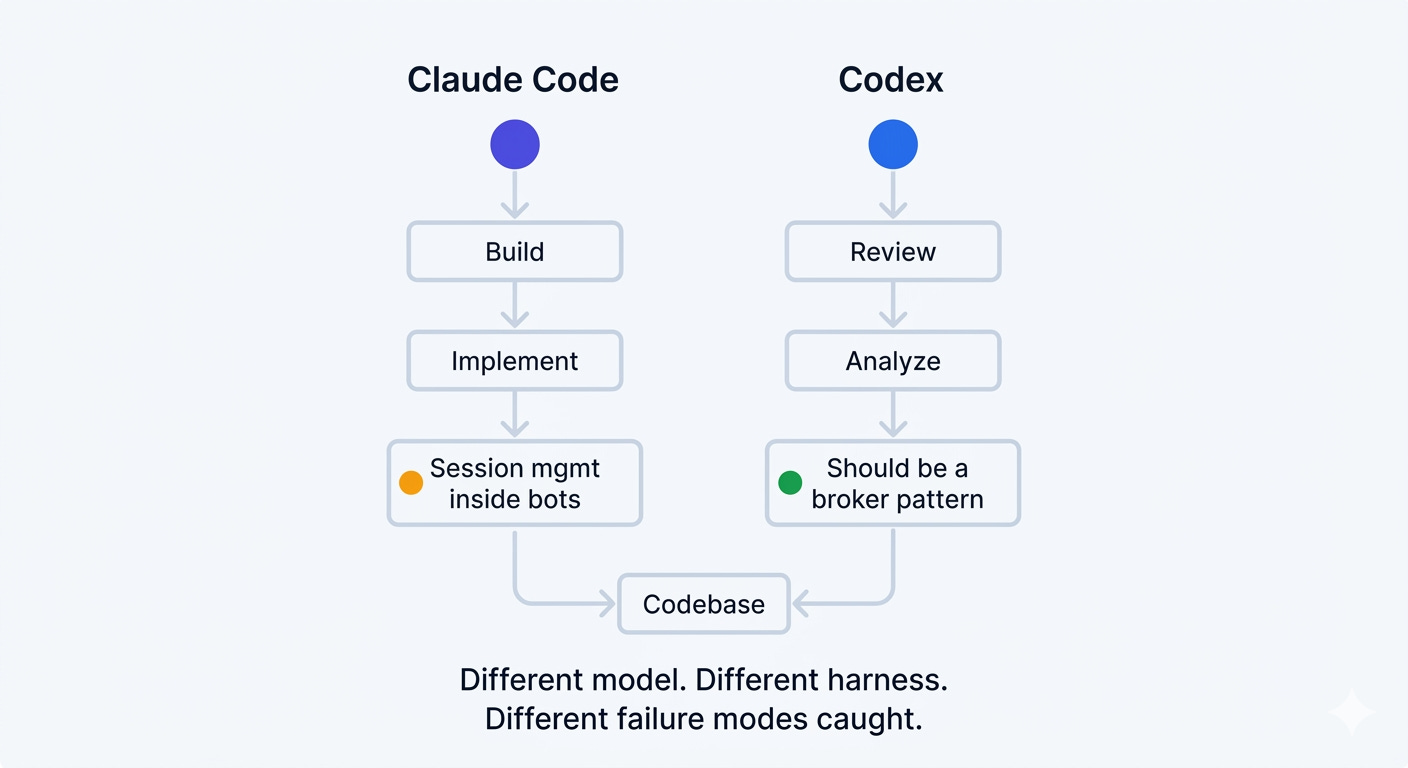
Now take a harder task: build a shared Slack bot framework with a common harness so non-engineering teams can upload their bots.
This is not five cycles. This is fifty. The agent needs to reason about session management architecture, authentication flows, plugin isolation, and deployment patterns. It needs to read documentation, explore existing code, draft a plan, implement, test, and iterate.
I used Claude Code to build the initial repo. The loop ran for close to an hour. It produced roughly 2,000 lines of working code. It made dozens of decisions along the way: which libraries to use, how to structure the plugin interface, where to put the session management logic.
And it got a critical architectural decision wrong.
It embedded session management inside individual bots. Each bot controlled its own session. For a shared framework where multiple bots run on a common harness, that is the wrong boundary. I needed a broker pattern where the framework owns sessions and bots register as delegates. The agent did not see this because the loop, no matter how many times it runs, is still bounded by the context and the specification it was given.
That is where the second agent came in. I gave the repo to Codex and asked it to review. Different model, different harness. Codex identified the session management issue immediately: “Your bots should not control the session. You want a broker. Each bot should register as a delegate.” It also flagged that the authentication flow needed centralization.
Two agents. Same codebase. Different failures detected.
We will come back to this when we get to the principles. For now, the point is structural. The loop is powerful. It is also bounded. A single agent in a single loop will confidently ship an architectural decision that a different agent, with different context, catches in five minutes. Two pairs of eyes. One problem. Minutes, not hours.
Simon Willison describes this loop in his Agentic Engineering Patterns guide with useful precision. The agent has a system prompt that defines the tools. The model generates a response. If the response contains a tool call, the harness executes it, appends the result to the conversation, and sends the whole thing back. If the response contains no tool call, the loop terminates. His words: “Believe it or not, that is most of what it takes to build a coding agent.”
When Anthropic’s source code was exposed in March 2026, the community confirmed this at production scale. The core orchestrator, QueryEngine.ts, implements a single-threaded while(tool_call) loop. No multi-agent swarms. No plan-then-execute pipelines. A flat loop with roughly 38 built-in tools, a permission system, and a context compression pipeline. The loop terminates naturally when the model produces text with no tool-use blocks.
Anthropic encoded their own design philosophy in their CLAUDE.md: “Do the simple thing first. Choose regex over embeddings, Markdown files over databases.”
Simplicity is the point. Loop is not sophisticated.
Harness is. And harness is where we have leverage.
The question is: why does this loop fail, and what can we do about it?
Why Agents Fail
We have seen the loop working. The signup form, five cycles, clean output. The Slack bot, fifty cycles, and an architectural decision the agent got wrong. The loop is powerful. It is also fragile, in specific, measurable ways. And always in the same three ways.
Three failure mechanisms explain most of what goes wrong.
Compound error, context overload, and specification vacuum.
All three are harness problems. None of them are solved by a better model.
Compound error
Every cycle of the loop is a decision. The agent decides what file to read, what tool to call, what pattern to follow, what test to write. In a typical feature implementation there are roughly twenty of these decisions. If each unguided decision has 80% accuracy, which is generous, the math is unforgiving.
0.8 raised to the power of 20 equals roughly 1%.
One percent chance the entire implementation is correct across all twenty decisions. That is not a hypothetical. Dziri et al. demonstrated at NeurIPS 2023 that transformer performance on compositional tasks decays exponentially as complexity increases. At 90% per-step accuracy across ten steps, overall reliability drops to 35%. At 95% accuracy across twenty steps, it drops to 36%. The curve is not linear. It is exponential. Small per-step improvements compound into large outcome differences, and small per-step degradations compound into catastrophic ones.
Dex Horthy at HumanLayer frames the same math from the practitioner’s side. A bad line of code is a bad line of code. A bad line of a plan could produce hundreds of bad lines of code. A bad line of research, a misunderstanding of how the codebase works or where functionality lives, could produce thousands of bad lines of code. The leverage cascade means human attention should concentrate at the highest-leverage point in the pipeline. That is the spec, not the implementation.
This is the math that kills vibe coding. An agent that gets each individual decision mostly right can still produce output that is, as a whole, wrong. Not because the model is incapable. Because the loop ran twenty times with no verification, no correction, no feedback at the decision points that mattered.
Context overload
The loop accumulates context. Every cycle adds tool results, file contents, error messages, reasoning traces. The context window is a finite resource. And the research on what happens as it fills is unambiguous.
Here is what we actually know. Liu et al. at Stanford demonstrated the U-shaped attention curve: language models attend most to information at the beginning and end of context, and significantly less to information in the middle. On multi-document QA, accuracy dropped by more than 30% when relevant information moved from position one to position ten. Chroma’s Context Rot study tested 18 frontier LLMs and found that every single model degrades as input length increases, even well below the stated context limit. Adding full conversation history dropped accuracy by 30% compared to a focused 300-token version of the same content. Stanford’s Meta-Harness work sharpened the point with a direct ablation: when the same agentic system received only scalar scores it reached 34.6% median accuracy, with LLM-generated summaries added it reached 34.9%, and with full raw execution traces it reached 50.0%. Summaries do not recover the signal. They remove it.
Long contexts are not free. They are actively harmful.
Every token we add is a tax on every token already there.
OpenDev team documented a sharp refinement of this for thinking-model contexts. Separate compressed long-range memory from verbatim short-range memory. Keep the thinking budget bounded regardless of conversation length. And critically, never iteratively summarize a summary. Always regenerate from the full history. Summaries of summaries accumulate distortion. The context stays small. The fidelity does not decay. In production harnesses, these compaction moves carry names and fire at graduated thresholds (HISTORY_SNIP for light trimming, Microcompact for targeted summarization, CONTEXT_COLLAPSE for aggressive consolidation, Autocompact as the final bounded rewrite). Graduated, not binary.
And here is what that means for the loop in practice. An agent that runs for thirty cycles accumulates context with every iteration. By cycle twenty, the instructions from cycle one are buried in the middle of the window, precisely where models attend least. The agent does not crash. It degrades gracefully. Which is worse. It starts ignoring instructions. It hallucinates with confidence. That is not randomness. That is the attention curve expressing itself.
Practitioners have converged on a heuristic: performance degrades meaningfully around 70% context utilization. HumanLayer’s research through an API proxy reported that Claude Code’s system prompt already contains roughly 50 built-in instructions.
The agent has a finite attention budget. Every unnecessary token spends it.
Specification vacuum
The third failure mechanism is the most common and the least discussed. When we give the agent a vague instruction, the loop does not stop and ask for clarification. It runs. Confidently. In whatever direction the model’s priors suggest.
UC Berkeley’s MAST taxonomy found that specification and system design issues account for the largest category of agent failures. Not hallucination. Not tool errors. Specification. The agent was never told what “done” looks like, what patterns to follow, what boundaries to respect. So it made those decisions itself, twenty times, through the loop, with the compound error curve working against it at every step.
We would not tell a new-hire “go fix the backend” with no context. We would give them the onboarding doc, point them to the right files, explain the architecture. The same discipline applies to agents. The specification is not optional. It is the scaffolding that makes the loop productive instead of destructive.
The Terminal Bench 2.0 leaderboard makes all three failure mechanisms visible in a single data point. On that benchmark, the same model, Opus 4.6, scored at position 33 in one harness and position 5 in another. Same model. Same benchmark. Same tasks. The only variable was the harness: the tools, the context management, the verification loops, the instructions. HumanLayer documented this gap explicitly.
The difference between position 33 and position 5 is not intelligence. It is engineering.
That is the premise for everything that follows. Models are getting better. They will continue to get better. But compound error, context overload, and specification vacuum are not model problems. They are harness problems. And the six principles we are about to introduce are the engineering discipline that addresses all three.
Six Principles of Agentic Engineering
The three failure mechanisms show up every day, in every agent, on every task. Compound error compounds. Context overloads. Specifications go missing. The six principles that follow are the engineering discipline that addresses all three.
These are not coding tips. They are harness design patterns. They apply to any agent at any autonomy level. The same principles hold when the domain is tax notice investigation and the stakes are a customer’s money. We will get there shortly.
The six form an arc.
Configuration orients the agent.
The spec tells it where to go.
Tests prove it arrived.
Architecture enforces the path.
Review catches what enforcement misses.
Failures feed back into the harness.
Each principle builds on the one before it.
They also share a stance. Graduated, not binary. Bounded, not unlimited. Empirical, not theoretical. Graduated context compaction beats a single emergency button. Bounded reminder budgets beat unlimited directives. Empirical threshold tuning beats first-principles derivation. That stance runs underneath every principle that follows. Treat the LLM as a fallible component embedded in a system designed to compensate for its failure modes.

Principle 1: Map, not manual
The agent is going to reason over whatever we give it. So we need to give it a map, not a thousand-page instruction manual.
HumanLayer’s research through an API proxy reported that frontier LLMs can follow roughly 150 to 200 instructions with reasonable consistency. Claude Code’s system prompt already contains about 50. That leaves room for maybe 100 to 150 of ours before quality degrades uniformly across everything. Every unnecessary line dilutes every other line. Liu et al. showed that models attend least to information positioned in the middle of the context window. Anthropic’s Agent Skills architecture implements the solution: progressive disclosure across three tiers. Only skill names and descriptions load at startup. The full SKILL.md loads when relevant. Reference files load on demand.
CLAUDE.md is not a single file either. It loads from multiple scopes in layered order: organization, user, project root, parent directories, child directories. Import syntax splits large instruction sets across files so each scope stays focused and the agent sees only what the current path needs. The map is assembled at runtime, not authored as a monolith.
In practice, CLAUDE.md should read like an onboarding doc for a new-hire intern. Project overview in two lines. Tech stack. Key commands: test, build, lint. Architecture patterns. Critical warnings. Under 200 lines. OpenAI’s Harness Engineering team runs their AGENTS.md at about 100 lines. HumanLayer recommends under 60.
What earns a line? Here is the test we use. A line earns its place if the agent would otherwise waste a cycle discovering it. “Use pnpm, not npm. The workspace lockfile lives at the repo root.” Two sentences. Saves the agent a lockfile hunt in every single session. “Database migrations run through Prisma, never raw SQL.” One line. Prevents an entire category of wrong-shaped pull request. Lines that do not meet that bar get cut. Every line that stays must earn the tokens it costs.
Dex Horthy calls the operational technique “frequent intentional compaction”: design your entire workflow around context management. Keep utilization in the 40 to 60 percent range. Split work into research, plan, implement. Compact between each phase so the agent starts each stage with a clean, focused context window.
Three moves from the OpenDev team are worth naming because they generalize.
First, lazy discovery: load tool metadata at startup, defer full schemas until a tool is actually selected. Eagerly loading 100 MCP tools consumes 40% of the context before the first user message. Lazy discovery reduces that to under 5%.
Second, filesystem offload. When a tool produces output exceeding a threshold, write the full content to a scratch file and return a short preview plus a reference. This turns a context-consumption problem, paid on every subsequent LLM call, into a retrieval problem, paid once only when needed. Retrieval is strictly cheaper.
Third, the design rule underneath both: every resource that grows with session length must have a cap. Undo history. Iteration limits. Nudge budgets. Concurrent tool calls. Unbounded resources fail in long sessions.
When Anthropic’s source code was exposed, we saw this principle in production. The system prompt is not monolithic. It is dynamically assembled from dozens of modular sections, split into a static cacheable half and a dynamic user-specific half. Memory is stored as a lightweight index at roughly 150 characters per entry. The agent is instructed to treat its own memory as “a hint, not truth” and verify against the actual codebase before acting.
The agent that remembers less but verifies more outperforms the agent that is told everything upfront.
Configuration orients the agent. It tells the agent where it is. The next question is where it is going.
Principle 2: Spec before code
The compound error math makes the case. Twenty unguided decisions at 80% accuracy each: 1% chance of a correct outcome. Resolve 15 of those 20 in a specification and the agent only needs to get 5 right. 0.8 to the fifth is 33%.
A 33x improvement from planning alone.
Minutes on the spec save hours on implementation. Sometimes days. The leverage is not in how fast we type. It is in where we choose to concentrate attention.
Every major coding agent now ships a planning mode. Claude Code: Shift+Tab. Codex: plan option. Cursor: plan mode. The workflow is the same across all three. Clear the context. Ask the agent to draft a plan. Review. Annotate corrections. Send it back: “address all notes, do not implement yet.” Iterate until zero ambiguity remains. Commit the spec to the repo.
The spec is not pseudocode. It is requirements, design decisions, test plans, boundary definitions. The kind of document a staff engineer would write as an RFC. That is exactly what the agent needs. A contract it can execute against in the loop.
Here is the template we use:
## Objective
The problem we are solving and why it matters.
One or two sentences. The "why" is not decoration.
The agent uses it to reason about trade-offs the
spec did not anticipate.
## Files in scope
The specific files the agent is allowed to touch.
## Architecture decisions
The patterns the agent must follow. Middleware chain,
not inline. Existing validation helpers, not new ones.
## Test plan
The cases that prove the implementation is correct.
Happy path and edges.
## Done-when
Observable state changes, not activities. Not "agent
writes validation logic." Rather: "the signup form
rejects malformed emails at the field boundary and
all five test cases pass."
## Boundaries
What the agent must not do. What requires escalation.
Two details in this template do more work than they look like they do.
The Objective is not a task name. It is the problem and the reason it matters. Paweł Huryn makes this point sharply in his Intent Engineering framework: a weak objective says “handle customer support tickets,” a better one says “help customers resolve issues quickly so they can get back to work, without creating more frustration than they started with.” The weak version tells the agent what to do. The better version gives the agent something to reason with when the spec runs out. Our coding specs deserve the same discipline.
The Done-when section describes states, not activities. The agent’s job is not to write validation logic. The agent’s job is to produce a signup form that rejects malformed emails at the boundary, with five passing tests that prove it. Activities are what the agent does. Outcomes are the state that exists after. We specify the outcome and let the agent figure out the activity.
Horthy’s leverage cascade validates this from the practitioner side: human review at the research and planning stages produces disproportionate returns compared to review at the implementation stage. Focus attention where leverage is highest.
Claude Code source validated this at the micro level: the agent cannot modify a file it has not first read. Understand before you act. Plan before you implement.
UC Berkeley’s MAST taxonomy found specification and system design failures to be the largest single category of agent failures. The fix is not a better model. It is a better spec.
The spec declares what done looks like. Tests prove it.
Principle 3: Tests as guardrails
The agent runs in the loop: reason, act, observe. It needs something to observe. Without tests, the observation step is the agent re-reading its own code and deciding it looks fine. That is not verification. That is self-review.
LangChain identified this as the most common failure pattern on Terminal Bench. Agents wrote solutions, reviewed their own output, and stopped. No actual testing. Just confidence.
The fix is TDD. Write the tests from the spec before the agent writes any code. All tests fail. Good. That is the starting state. Now the agent has a verification signal in the loop. It implements, runs the tests, observes failures, iterates. The loop does not finish until the tests pass. These agents can run for thirty minutes, an hour. If the tests are in place, we can let them run. That is the trade: write the tests up front, pressure-test them against the spec, and reclaim the next hour of our time.
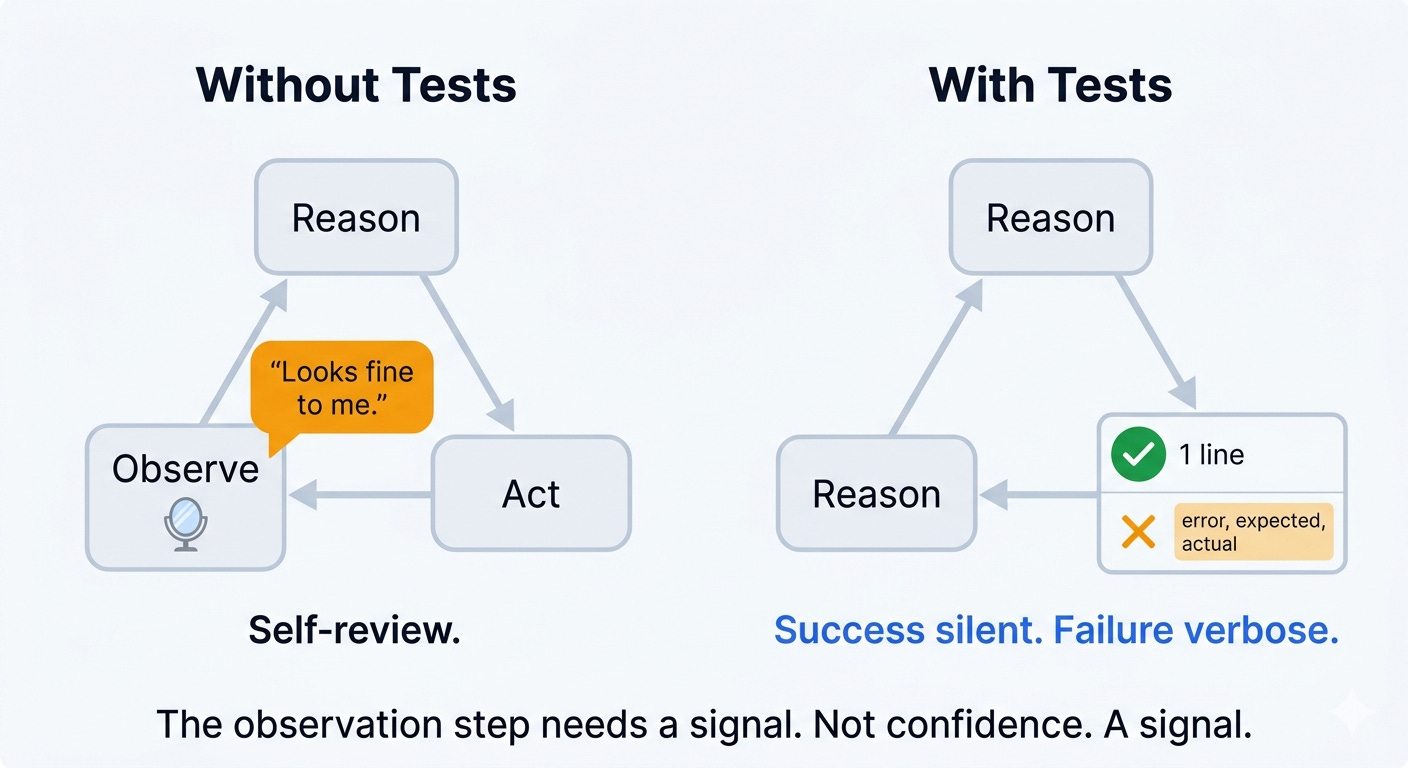
Now the backpressure design is where most teams leave leverage on the table. The principle is simple: success is silent, failure is verbose. A passing test produces one checkmark. A failing test dumps the specific error, the expected value, the actual value, the stack trace.
We control what enters the context window, and we control it by controlling what the tools say. This asymmetry keeps the context window clean and gives the model exactly the signal it needs to self-correct. When tests pass, the model sees one line and keeps moving. When tests fail, the model sees the full error and reasons about what to fix. No noise in the smart zone. Maximum signal at the point of failure. Most test runners default to the opposite. They print every test name, every passing assertion, every timing metric. That is a context-overload machine. The tool’s output is not a log for humans. It is context for the model. Design it that way.
Simon Willison makes a subtle but important refinement in his Agentic Engineering Patterns: first run the existing tests before changing anything. Establish a baseline. Know what was passing before the agent started. That way we distinguish between tests the agent broke and tests that were already broken.
TDAD paper (Test-Driven Agentic Development, March 2026) quantified the impact. Targeted test context reduced regressions by 70% on SWE-bench Verified. But adding generic TDD instructions without targeted test context made regressions worse. The agent needs structured test context as part of the harness scaffolding. Not instructions to “write tests.” The academic literature calls this “validator-driven feedback”: deterministic signals that evaluate outputs against predefined correctness criteria. Tests are the most accessible form of that pattern.
In the Claude Code source, the Edit tool implements this principle at the operation level. Exact-string-replacement requires the old string to match uniquely in the file. If it matches zero times or more than once, the tool returns a structured error: “old_string appears 3 times in file. Please provide more context for a unique match.” The uniqueness constraint is a test baked into the tool itself.
OpenDev’s edit tool shows the same discipline inverted: a 9-pass fuzzy matching chain absorbs whitespace drift and escape-sequence mismatches before the edit fails. Both designs accept the same premise: LLMs produce approximately-correct outputs. Design tools to absorb imprecision as a first-class property.
Tests catch what the agent did. The next principle shapes what the agent can do.
Principle 4: Hooks, not instructions
Writing “CRITICAL: always run the type checker” in CLAUDE.md and hoping the model follows it is not engineering. It is prayer.
The distinction matters quantitatively. Dotzlaw Consulting’s analysis reported that prompt-based instructions achieve 70 to 90% compliance. Hooks achieve 100%. A hook is a deterministic check wired into the agent’s execution lifecycle. It fires every time. The agent does not choose whether to run it. It cannot reason its way around it. It cannot forget it when the context window is 85% full.
In practice: pre-commit hooks that run the formatter, the type checker, the linter. Claude Code hooks that execute at specific lifecycle points, PreToolUse, PostToolUse, Stop.
Here is the kind of hook that pays for itself in the first week. A team we talked to added a PreToolUse hook that greps every staged diff for strings matching AWS_SECRET, sk_live_, or a filename ending in .env. If it finds one, the commit is blocked before the agent even sees the response. Deterministic. Every single time. No prompt can promise that. The agent cannot forget a hook that fires before the agent thinks. It cannot talk its way past it. It cannot argue that this particular .env is fine. That is the difference between steering and enforcement.
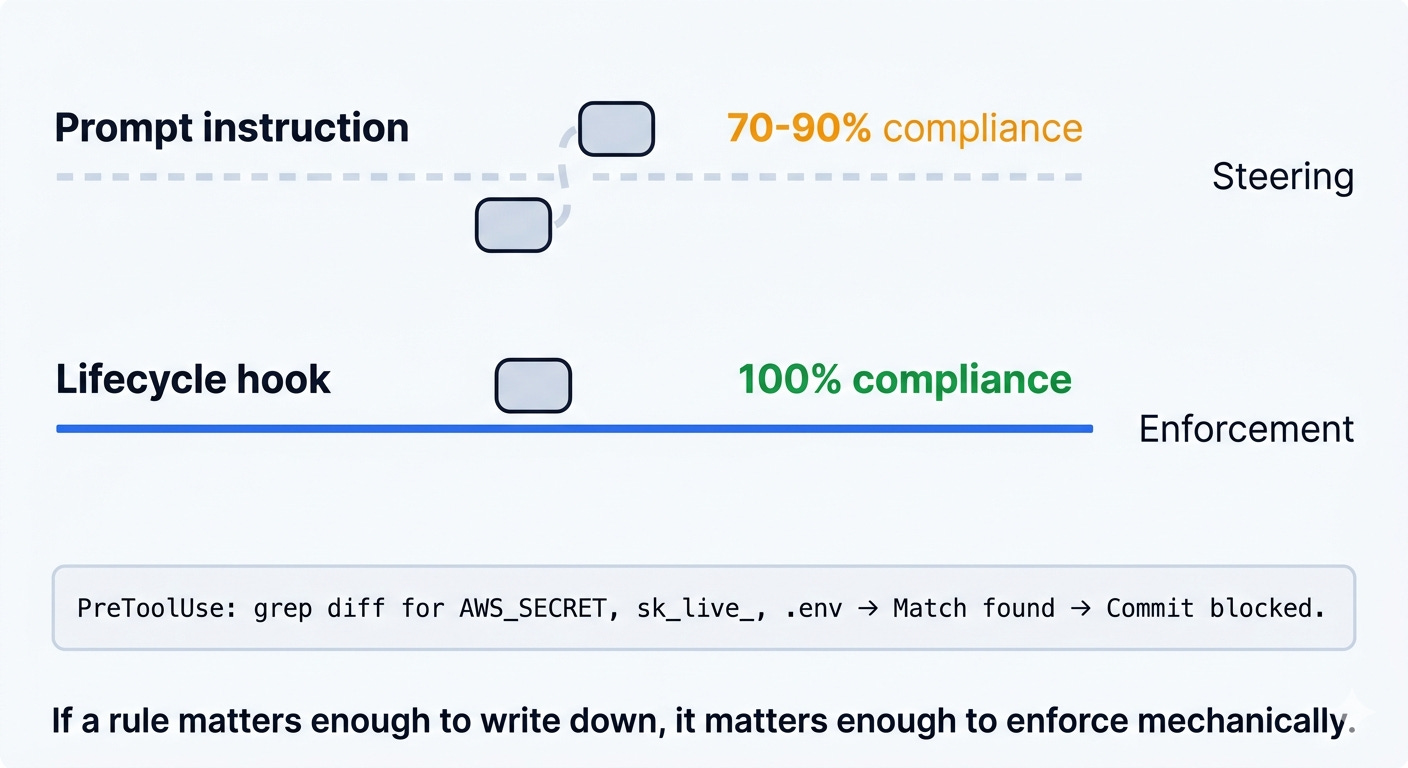
The distinction is steering versus enforcement. The prompt is where we steer. The harness is where we enforce. Confusing the two is how agents ship type errors on Tuesday and credential leaks on Thursday.
Now here is the sharper version of this principle, and it comes from the OpenDev team. The most robust enforcement is not a hook that blocks a forbidden action. It is a tool schema that does not contain the forbidden action at all. They call it making unsafe tools invisible, not blocked. Schema gating is structurally stronger than runtime permission checks because the agent cannot reason around a capability it does not know exists. The difference between a guard rail and a missing road. The model cannot argue for an exception to a tool that is not in its schema.
Claude Code source revealed a six-layer permission gauntlet: input validation, blanket deny rules, tool-specific checks, pattern-matching allowlists, mode-specific logic, and a circuit breaker. The Auto permission mode runs a separate smaller classifier model evaluating safety independent of the inference that generated the action. If the classifier is unavailable, the action is denied.
That is not an instruction. That is architecture. Deterministic beats probabilistic. Every time.
If a rule matters enough to write down, it matters enough to enforce mechanically.
Sub-agents as context firewalls
Hooks handle enforcement. Sub-agents handle something different: context isolation. When the main agent needs to research something, that research happens in an isolated context window. Only the condensed answer flows back to the parent. The parent’s context window is not polluted by research artifacts, failed searches, or intermediate reasoning. This is a structural pattern, not just a tactic. The parent stays in the smart zone because it never sees the raw material. It sees the conclusion. That is the firewall.
Horthy makes this point directly: sub-agents are about context control, not anthropomorphizing roles. The parent stays clean. The sub-agent does the noisy work and returns a structured summary. The canonical use case: “find the existing rate-limiting package and its integration points.” That task could consume 20,000 tokens of grep output, package-manifest reads, and middleware traces. The sub-agent does all of that in its own context. The parent receives: “express-rate-limit is installed at middleware/index.ts:47, currently unused.” Twelve words back to the parent. Twenty thousand tokens of raw material stay behind the firewall.
Hooks enforce what the agent must do. Sub-agents protect what the agent must think about. Both are the harness doing work the prompt cannot.
Enforcement catches mechanical errors. It does not catch judgment errors. That is what review is for.
Principle 5: Cross-agent review
Recall the Slack bot example. Claude Code built the framework and embedded session management inside individual bots. Codex reviewed the same repo and immediately identified the architectural issue: sessions should be owned by a broker, not by individual bots. Two agents. Same codebase. Different failure modes caught.
This is not surprising once we understand the equation. Different models have different training data, different attention patterns, different failure modes. Different harnesses manage context differently, present tools differently, structure instructions differently. The combination covers more ground than either alone.
LangChain’s Terminal Bench data showed that the same model scores differently across different harnesses. A harness that catches certain categories of bugs will miss others.
The theoretical foundation runs deeper than “different models catch different bugs.” Evans et al. at Google demonstrated that frontier reasoning models like DeepSeek-R1 do not improve simply by “thinking longer.” They simulate multi-agent-like interactions within their own chain of thought, what the researchers term a “society of thought.” Internal debates among distinct cognitive perspectives that argue, question, verify, and reconcile. None of these models were trained to produce this behavior. It emerged from optimization pressure alone.
Robust reasoning is a social process, even within a single mind.
Cross-agent review externalizes that dynamic across models and harnesses, with the advantage that external perspectives are genuinely independent rather than simulated.
Willison’s framework validates the same logic from a different angle. His emphasis on exploratory prototyping, using agents to cheaply test multiple approaches before committing, is cross-agent review applied to the design phase instead of the verification phase.
Claude Code sub-agent architecture implements three coordination models. Fork: byte-identical copy of parent context, reusing the prompt cache. Teammate: separate terminal with file-based mailbox communication. Worktree: isolated git branch for risky exploratory work. Sub-agents cannot spawn their own sub-agents, preventing recursive explosion. The architecture assumes that no single context window sees everything.
Two agents catch mechanical issues. Our review catches product intent, architecture, the right abstraction. That is where taste matters.
Review surfaces what we missed. The question is what we do with that signal.
Principle 6: Failures as harness feedback
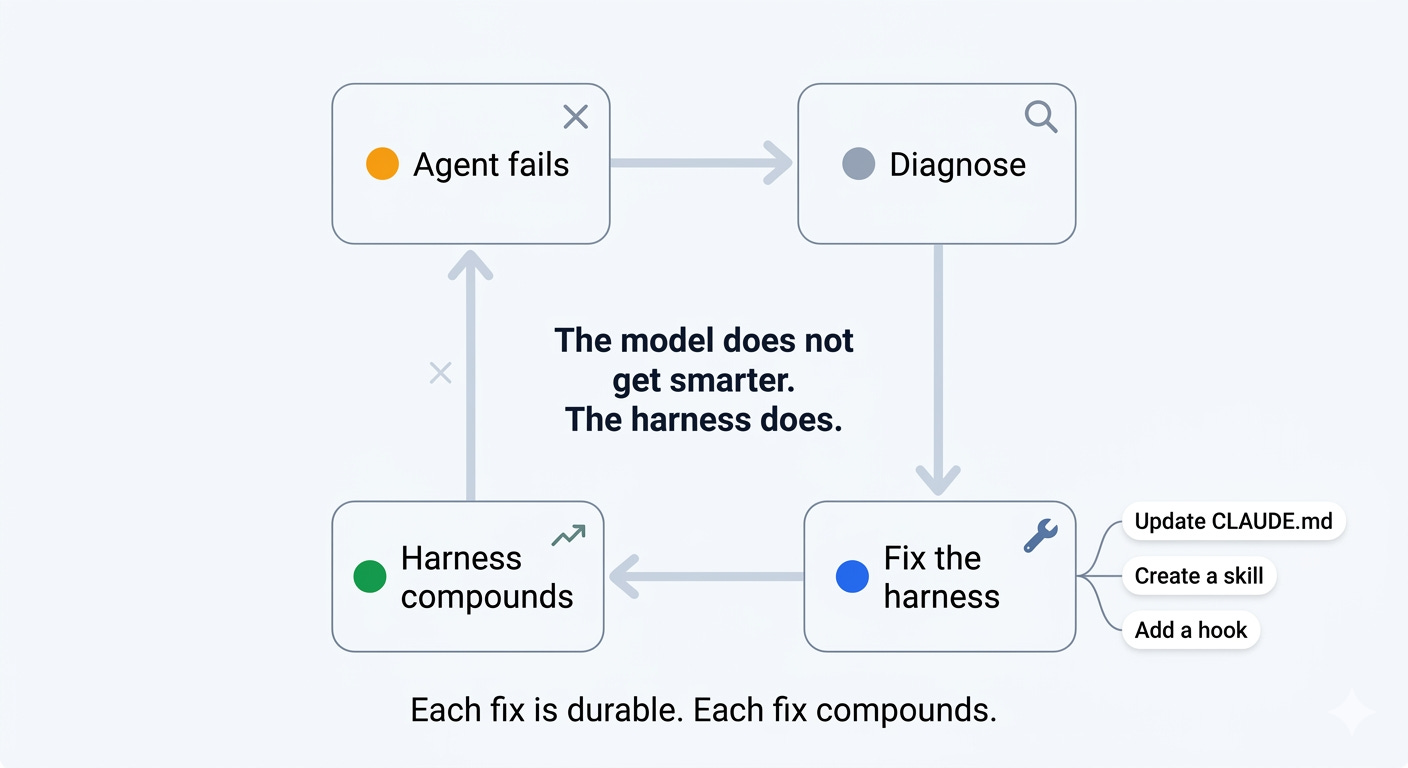
When the agent fails, the instinct is to fix the prompt. Reword the instruction. Add more detail. Try again. That instinct is wrong.
The prompt is the most fragile component of the harness. It competes for attention with everything else in the context window. It is subject to the U-shaped attention curve. It degrades as context fills. A fix that lives in the prompt will break the next time context is tight.
The right response to an agent failure is a harness improvement. Wrong directory? Update CLAUDE.md. Bad environment config? Create a skill. Type errors shipping? Add a hook. Same mistake recurring? Build a review checklist. Each fix is durable. Each fix compounds.
Here is what that looks like in practice. A team had an agent that kept calling a deprecated payments API they had retired six months ago. The old endpoint still existed. The docs still lived in the training data. Every few runs, the agent would confidently reach for it and the tests would catch the error. The team’s first instinct was the obvious one: add a line to CLAUDE.md saying “do not use the v1 payments API.” That worked for a week. Then the CLAUDE.md grew, the line moved to the middle of the window, and the agent forgot. So they tried a different move. They wrote a three-line skill called payments-api-migration. It lived in the skills directory and loaded only when a file under /payments/ was in scope. It said: “We use v2. v1 is deprecated. Here is the one-line diff from v1 to v2.” The next ten runs used v2 without being told. The one after that used v2. And the one after that. The failure became a skill. The skill became durable. The harness got smarter and the prompt got shorter.
Model does not get smarter. Harness does. That is the flywheel.
Willison describes this as the “compound engineering loop.” Dan Shipper and Kieran Klaassen at Every codified the practice: every completed project ends with a retrospective, a “compound step” where what worked gets documented for future agent runs. LangChain operationalizes it through LangSmith’s Insights Agent, which analyzes production traces, clusters failure patterns, and surfaces root causes for prioritized improvement.
Wei et al.’s survey formalizes this as the “self-evolving” layer of agentic reasoning, with a meta-update rule: the evolvable system state updates based on feedback from each episode. They categorize three types of evolution.
Verbal: updating textual reflections and guidelines. That is updating CLAUDE.md and skills.
Procedural: expanding the tool library. That is adding hooks and skills.
Structural: changing the agent’s architecture itself. The model stays the same. The harness compounds.
The OpenDev team surfaced a practical discipline that sits underneath this flywheel. Empirical threshold tuning over first-principles calculation. Specific values for caps, compaction thresholds, nudge frequencies, iteration limits resist theoretical derivation. They depend on interactions between model behavior, user workflows, and system overhead in ways that are hard to predict upfront. OpenDev’s 70% compaction trigger, 3 nudge attempts, and 6 thinking depth levels all emerged from iterative failure analysis, not from calculation. Start conservative. Tune based on observed failure modes.
Mitchell Hashimoto, who coined the term harness engineering, put it most directly: “Any time your agent makes a mistake, you take the time to engineer a solution so the agent never makes that mistake again.”
Model contains the intelligence.
Harness makes it usable.
Six principles are how we build harnesses that compound.
The Design Stance
OpenDev team, in an independent technical report on a terminal-native coding agent, arrived at the same stance from a different direction. They organized their reflection around five design tensions, not six principles, but the meta-pattern is identical. The LLM drifts in attention, produces approximately-correct outputs, acts prematurely when tools are available, and reasons around runtime checks. Good harness architecture does not fight these tendencies. It structures the environment so that failures either become impossible, get absorbed transparently, or self-correct through just-in-time nudges.
One tension from that work deserves its own attention because it cuts across several principles rather than sitting inside any one of them. System prompt influence decays. Instructions that reliably govern the first few turns get violated after 30 or more tool calls, when they are buried under dozens of tool results. The fix is tactical. Inject reminders at the point of decision, not upfront. Use role: user, not role: system. Cap reminder frequency or the model learns to ignore them. Separate thinking from action by removing tool schemas from the thinking-phase API call entirely. The absence of tool schemas, not the instruction to think carefully, is what changes model behavior.
There is also a harness operation that runs when nothing is happening. Background consolidation reviews accumulated memory during idle time, deduplicates overlapping notes, prunes stale entries, and reorganizes what remains so the next session starts clean. Call it dream consolidation, call it memory hygiene, call it garbage collection. The point is the same. Memory quality is a harness property, not a model property. The model does not tidy itself. The harness has to run the sweeper.
Fallibility is the premise. Compensation is the design move.
Under the Hood
The six principles were illustrated with coding agents because that is the context most readers share. Claude Code, Cursor, Codex. Tools we use every day. But the claim of this article is broader. These are not coding agent principles. They are agent engineering principles.
The way to test that claim is to take the same six principles into a domain where the stakes are higher, the context is messier, and the loop runs against production data that affects real customers. Tax operations.
A notice arrives from a state tax agency. A PDF. It says a company owes $4,200 for Q3 2025. A Tax Ops specialist’s first question is not “how do we pay this?” It is: “Is this real?”
That question sounds simple. It is not. Answering it requires reasoning across time, across systems, and against policy. The notice might be what the team calls “crossed in the mail,” a notice generated before a fix but arriving after. The balance might differ from a prior case by $0.47. Under the team’s decision framework, if the difference is less than a dollar, close it. If more than a dollar, keep it open and transfer.
Forty-seven cents decides whether this case takes two minutes or two hours.
We built an agent to handle this. The Tax Notice AI system. It is a LangGraph ReAct agent. The same loop. The model reasons. It calls tools. It observes the results. It reasons again. It submits a diagnosis.
The architecture has four stages. Ingest the Salesforce case and download the notice. Extract structured data from the PDF using a vision LLM. Run the diagnostic agent to determine root cause. Generate two comments, one internal and one customer-facing, through a response agent.
Same equation. Same loop. Different domain. Different tools. Different stakes.
So what actually happens when this notice hits the system?
The PDF enters the extraction stage first. A vision LLM reads the notice and pulls out structured fields: jurisdiction, period, balance, notice type, agency contact. The extraction returns with a confidence score of 0.87. That is below the pipeline’s threshold of 0.9, so Gemini fires automatically as a second-pass extraction against the same PDF. Different model, different architecture, different failure patterns. The two extractions agree on every field. The balance is $4,200.47. Confidence gets recalculated, and the extraction is promoted. No specialist decided to get a second opinion. The harness enforced it at a hardcoded threshold.
Before the diagnostic agent sees any of this, six deterministic triage rules run. Think about that for a second. Before the model reasons, before the loop starts, before a single token gets spent, the harness already has a chance to close the case. PEO cases follow predictable patterns, and those patterns have been encoded into rules that resolve cases in milliseconds without invoking the agent loop at all. Is the notice period before the client’s first check date? Is there a prior case for the same period and jurisdiction? Is there a duplicate notice for the same agency? The third rule finds a match. A prior case for the same period and the same jurisdiction was resolved eighteen days ago. The balance on that prior case was $4,200.00. The delta is $0.47. Under the team’s decision framework, if the difference is less than a dollar, close it as crossed in the mail.
Forty-seven cents decides this case in the triage layer. The agent loop never fires. The spec runs first, and the spec handles what the spec can handle.
Hold the counterfactual for a moment. If the prior-case check had returned empty, the case would have passed to the diagnostic agent, and the loop would have started. The first thing the agent would do is load a skill. Not all twenty. The one that matches. “Account-number-mismatch.” “Missing-payments.” “Notice-crossed-in-mail.” “Deposit-schedule.” “Filing-exclusions.” Each skill is a lightweight playbook in plain language. It tells the agent what evidence to look for, which database queries to run, which patterns are typical for that case type. The agent does not carry all twenty playbooks in its context window at once. It loads the one that matches. Progressive disclosure, the same architectural pattern as CLAUDE.md and Agent Skills, applied to a tax workflow.
Back to the actual case. The triage classifier has routed it to close as crossed. The system generates a diagnosis: crossed in the mail, $0.47 discrepancy, prior case reference attached. Then it checks whether the diagnosis is shippable.
A deterministic validation layer runs against the completed diagnosis. It asks a simple question: did the evidence the agent relied on actually exist? Did the core queries succeed? Did the required prior-case reference resolve to a real record? If any of those checks fail, the system overrides the diagnosis to unknown, sets confidence to zero, and marks the case for manual review. The design philosophy is explicit: prefer lower confidence plus escalation over false certainty. The agent cannot ship a diagnosis the validation layer does not trust, any more than a coding agent can ship code past a failing test.
The validation passes. The diagnosis is accepted. The response agent generates two comments. One internal, for the case record. One customer-facing, for the email back to the client. Both get written into a persistence layer alongside the diagnosis.
A Tax Ops specialist opens the case, reviews the diagnosis, reviews the customer-facing comment. Most of the time, they send it. Sometimes they edit. When they edit, every edit gets logged. The system tracks edit rates by case type, by jurisdiction, by playbook. When the edit rate on “notice-crossed-in-mail” customer comments starts climbing, that is a signal. It means the generated language has drifted from what specialists consider appropriate, or something about the domain has changed. The playbook gets updated. The next case handled with that playbook is handled slightly better. The model did not get smarter. The harness did.
That is the same flywheel Hashimoto described. The same compound engineering loop Willison named. Applied to a domain where the output is not a pull request but a diagnosis that determines whether a customer owes $4,200. Same primitives. Same data flywheel. Different stakes.
Six principles fired inside this one case. Some fired automatically in a fraction of a second: triage rules, confidence-gated second-pass extraction, validation override, edit-rate logging. Some would have fired if the case had needed them: skill loading, the full diagnostic loop. None of them are the model. All of them are the harness.
The effect on the team is not faster case handling. That is the first-order change and it is real, but it is not the interesting one. Cases that used to take two hours close in seconds. Cases that used to require a senior specialist route to an automated triage. The interesting change is a shifted distribution of what specialists do. Routine cases like this one, crossed in the mail, duplicate notices, pre-Rippling periods, close in seconds without specialist review. What lands in specialists’ queues now is the cases the harness cannot handle: policy questions, jurisdictional edge cases, disputed amounts where the evidence conflicts, situations where the right answer depends on judgment the harness has no basis to make. Specialists spend their time where judgment matters. The harness handles the rest.
The coding agent and the tax notice agent are not analogous systems.
They are the same system.
The same equation. The same loop. The same six principles. The only variables are the tools, the domain knowledge, and the consequences of getting it wrong. Everything else is identical.
Agentic engineering is not a coding practice. It is an engineering discipline.
Harness is the unit of design. Loop is the primitive.
Principles are the constraints that make the loop productive.
Whether the agent is writing validation logic or investigating a crossed-in-the-mail tax notice, the discipline is the same.
The Identity Shift
We are not code writers anymore. We are harness engineers and orchestrators.
That sentence sounds like a slogan. It is not. It is a description of what has already happened to the work. Hours of current work, compressed into minutes. Days of integration, compressed into hours. Weeks of specification churn, compressed into a single spec review.
Think about what we actually did across the examples in this article. We did not write validation logic for the signup form. The agent did. We did not write the Slack bot framework. The agent did. We did not manually investigate the $4,200 tax notice, cross-referencing payments, filings, and policy across three systems. The agent did. What we did was design the harness that made each of those outcomes possible. The CLAUDE.md that oriented the agent. The spec that constrained the loop. The tests that gave the loop a verification signal. The hooks that enforced what the prompt could not. The review that caught what the first agent missed. The feedback that made the harness better for next time.
Specification quality. Review rigor. Problem decomposition. Architecture. Taste.
Those are the skills that determine outcomes now. Not typing speed. Not language fluency. Not memorizing APIs. The engineers who invest in these skills are compressing weeks into days and days into hours. The engineers who do not are running the same treadmill faster.
OpenAI demonstrated this at scale. A team of three engineers, later seven, used Codex agents to ship a production application with roughly one million lines of code. Zero lines written by human hands. 1,500 pull requests. 3.5 merged PRs per engineer per day. The humans did not write code. They wrote specs, reviewed output, and improved the harness.
Dex Horthy at HumanLayer arrived at the same place from the practitioner side: “I can count on one hand the number of times I have edited a non-markdown file by hand in the last three months.” He and his team shipped a bug fix to a 300,000-line Rust codebase they had never worked in before. The PR was approved by the maintainer the next morning. Then they shipped 35,000 lines of code in seven hours for features estimated at three to five days of senior engineer time. Not by writing Rust. By writing specs, reviewing research, and compacting context.
Willison names the economic shift underneath this: writing code is cheap now. But good code still has a cost. That cost has moved from implementation to judgment. The agent produces options. We supply taste. We generate variations, pressure-test, iterate. Ship quality that is faster and obviously better. That is the difference between vibe coding and craftsmanship.
The METR study offers a necessary caution. Sixteen experienced open-source developers, randomly assigned to use or not use AI tools, took 19% longer with AI on tasks in their own mature repositories. They predicted AI would make them 24% faster. The gap between expectation and reality was 43 percentage points. The researchers’ conclusion was not that AI tools are useless. It was that experienced developers working in familiar codebases had already optimized their workflows, and the overhead of steering the agent exceeded the time saved. The harness was not tuned to their context.
Without proper harness engineering, raw AI tools can make experienced developers slower.
That finding reinforces the thesis. The tool is not the variable. The harness is the variable. The developers who get faster are the ones who invest in the harness: the configuration (P1), the specs (P2), the tests (P3), the hooks (P4), the review patterns (P5), the feedback loops (P6). The six principles named. Developers who ran them, even without calling them that, got faster. Developers who treated the agent as a chat interface got slower.
Anthropic’s 2026 Agentic Coding Trends Report found that developers use AI in roughly 60% of their work but can fully delegate only 0 to 20% of tasks. That gap is the harness. Close it, and delegation expands. Leave it open, and we stay in the loop on everything, doing the current work we were supposed to be freed from. We should be honest about what this means. Models will continue to improve. Post-training optimization, where models learn better tool-use strategies through reinforcement learning, is real and complementary. But post-training is not the lever most practitioners control. The harness is. And for in-context reasoning, the evidence is clear: harness design is the primary determinant of agent performance.
Where the Harness Thesis Breaks
Every argument has a limit. This one does too.
The harness thesis says that for most agent systems most of the time, the dominant variable is everything around the model. That is defensible. It is also incomplete. There are cases where the model is the ceiling, and no amount of harness engineering gets past it.
Model capability ceilings are real. Give a 2021 model a perfect harness. Tools, hooks, verification loops, cross-agent review, the full six principles applied with discipline. It will not match what a current model does with a default harness. The harness amplifies intelligence. It does not create it. When we say harness engineering is the primary lever, we mean primary for practitioners working with frontier models. We do not mean the model does not matter. The model sets the range of what is possible. The harness determines what we reach inside that range.
Some tasks are bounded by training data, not orchestration. Genuinely novel reasoning, mathematical discovery, scientific hypothesis generation, creative synthesis at the edge of a field, does not respond to better tools or tighter specs. If the model has not been trained to reason about a class of problem, the loop will not discover the reasoning. Harness engineering helps the model apply what it knows. It does not help the model know what it does not know.
Long-context comprehension has a harness floor. Context compaction, filesystem offload, sub-agents as firewalls, all of it helps. But at some point, holding genuinely global structure in mind, tracing a change through a 500K-line codebase, reasoning about a legal document where the answer depends on interactions across dozens of clauses, requires architectural advances in attention itself. The harness can route around the ceiling. It cannot remove it.
Post-training is complementary, not replaceable. Reinforcement learning from verified rewards, tool-use optimization baked into the model weights, training signals from production traces: these are real levers, and they belong to model labs, not to practitioners. A coding agent that was RL-trained on tool use will beat an identically-harnessed coding agent that was not. The gap is real. It is also not something we control.
So here is the honest version. The harness is the primary lever for us. Model capability is the primary lever for the labs. Both are real. Both compound. The practitioner’s job is to max out the lever we control while the labs push the ceiling we do not. When the model improves, the harness that was tuned to compensate becomes overkill in some places and insufficient in others. The work continues.
The thesis is not that the model does not matter. The thesis is that most of the gap most practitioners experience between their agents and what they want their agents to do is a harness gap, not a model gap. Close the harness gap first. The model gap closes on its own, on someone else’s schedule.
We have explored previously how model labs are becoming agent labs, how trust frameworks earn agent autonomy through taxonomy, ownership maps, and design discipline. We have explored how sensemaking and articulation work give agents decision memory, turning human judgment into decision traces that compound into context graphs. This article adds the third layer.
Trust framework governs when to expand scope.
Sensemaking framework governs what the agent captures.
Agentic engineering governs how the agent works.
Three layers. One system.
The work ahead is not a research problem. It is a discipline problem.
We have the equation. Agent = Model + Harness. We have the loop. We have the six principles. We have production proof from coding agents, from enterprise operations, from every domain where the harness has been taken seriously. We know the pattern. We know the failure modes. We know the stance: graduated, bounded, empirical.
None of this is waiting on a better model. It is waiting on us.
Here is the ask. Pick one workflow this week. Not next quarter. This week. Write the configuration. Commit the spec. Add the hooks. Run the cross-agent review. Watch what breaks and fix the harness, not the prompt. Do this once, carefully, and the loop will teach us more than any article can.
Then share what worked with the team. Document the skills. Run a 45-minute weekly share. Make the harness a shared asset, not tribal knowledge that lives in one engineer’s head. Individual, team, organization. That is the ladder, and it is how production-grade agents actually get built.
If one is leading a team, this is the job now. Not writing the code ourselves. Building the harnesses our teams can trust. Go first. Model the behavior. Invite the team in. The engineers who will matter most over the next few years are not racing to try every new tool. They are compounding leverage one workflow at a time. Specification quality. Review rigor. Problem decomposition. Architecture. Taste. These are not extras on top of the craft. They are the craft now.
We are not being replaced. We are being concentrated. Minutes, not hours, on the work the agent can handle. Hours, not minutes, on the decisions that require us. That is the trade. That is the whole trade.
The loop is the primitive. The harness is the unit of design. The six principles are the discipline. The engineers who scale are not the fastest typists. They are the best orchestrators.
We know the way ahead. Pick the workflow. Build the harness. Ship the leverage. Start this week.
Here is what makes this moment different from every moment before it. Intelligence is at our fingertips. Not in a lab. Not behind a paywall. Not gated by a credential. It is in the terminal we already have open, the editor we already use, the agents we already run. That changes who gets to build. The answer is everyone. Engineers, of course. But also operators, designers, product managers, founders. Anyone with a problem worth solving and the taste to solve it well is now a builder.
And the discipline runs in both directions. Apply the six principles to the code we write with agents. Apply them to the agents we ship to our customers. Same equation. Same loop. Same craft. The harness we build for ourselves is the harness our users will feel. Configuration, spec, tests, hooks, review, feedback. Six moves. Two directions. One discipline.
This is the moment. Not next year. Not next quarter. Now.
Time to build.
This article is part of a series on agentic systems. The first explored how model labs are becoming agent labs. The second introduced a trust framework for earning agent autonomy. The third examined sensemaking and articulation work as the human layer context graphs need. This article addresses the engineering discipline that makes all three operational.
Appendix: Curated References
These are the sources we relied on most heavily, organized by how a reader might use them. Not a complete bibliography. A reading path.
Start here: the equation and the loop
Yao, S., Zhao, J., Yu, D., et al. (2022). “ReAct: Synergizing Reasoning and Acting in Language Models.” ICLR 2023. arXiv:2210.03629. The paper that introduced the Reason-Act-Observe loop. Every coding agent and enterprise agent in production today runs a variant of this architecture. Read this first to understand what the loop actually is.
Willison, S. (2026). “Agentic Engineering Patterns.” simonwillison.net/guides/agentic-engineering-patterns/. A practitioner’s guide that arrives at the harness framing independently. Short chapters. Concrete patterns. Willison’s “How Coding Agents Work” chapter is the clearest non-academic explanation of the loop available. His anti-patterns chapter is the most honest short list of what not to do.
Chase, H. (2026). “Anatomy of an Agent Harness.” LangChain Blog. Harrison Chase’s definition: “Every piece of code, configuration, and execution logic that is not the model itself.” The canonical industry statement of what a harness is and why it matters.
Inside Claude Code’s Architecture: What the Source Revealed. (March 2026). Community analysis of the accidentally exposed Claude Code source. 512,000 lines of TypeScript. The most thoroughly documented production agent implementation available. Read this to see what every one of our six principles looks like when implemented at production scale.
OpenDev Team (2026). “OpenDev: An Open Technical Report for a Terminal-Native Coding Agent.” Technical report. The most comprehensive public technical report on a production coding agent harness. Section 3’s Five Design Tensions are the clearest articulation of the cross-cutting engineering philosophy available in the literature: context as budget, steering over long horizons, safety through architecture, designing for approximate outputs, bounded resources. Read this alongside the Claude Code source exposure for two independent views into what harness engineering actually looks like at production scale.
Why agents fail: the research base
Dziri, N., Lu, X., Sclar, M., et al. (2023). “Faith and Fate: Limits of Transformers on Compositionality.” NeurIPS 2023. The paper behind the compound error math. Demonstrates that transformer performance on compositional tasks decays exponentially as complexity increases. The empirical foundation for why twenty unguided decisions at 80% accuracy produce 1% correctness.
Liu, N., Lin, K., Hewitt, J., et al. (2024). “Lost in the Middle: How Language Models Use Long Contexts.” TACL 2024. The U-shaped attention curve. Models attend most to the beginning and end of context, least to the middle. Explains why long-running agents degrade even when they stay within context window limits.
Hong, K., et al. (2024). “Context Rot: How Increasing Input Tokens Impacts LLM Performance.” Chroma Research. Tested 18 frontier LLMs. Every single model degrades as input length increases, well below stated context limits. The empirical case for ruthless context discipline.
Lee, Y., Nair, R., Zhang, Q., et al. (2026). “Meta-Harness: End-to-End Optimization of Model Harnesses.” arXiv:2603.28052. Stanford, KRAFTON, MIT. The sharpest single empirical result on compressed-feedback limits. A direct three-way ablation showed that an agentic system with access only to scalar scores reached 34.6% median accuracy, adding LLM-generated summaries barely moved the number to 34.9%, and full access to raw execution traces jumped it to 50.0%. The median of the full-trace condition beat the best candidate under either compressed condition. The paper also documents that in the agentic coding setting, a median iteration read 82 files worth of prior source code and execution traces. Cite this when the argument needs proof that summaries are not just lossy, they are actively harmful.
Cemri, M., Pan, M., Yang, S., et al. (2025). “Why Do Multi-Agent LLM Systems Fail?” UC Berkeley. MAST taxonomy paper. Analyzed 1,600+ agent execution traces across seven frameworks. Specification and system design failures account for the largest category of agent failures. Not hallucination. Not tool errors. Specification. The empirical foundation for why we need specs.
Horthy, D. (2025). “Advanced Context Engineering for Coding Agents.” HumanLayer Blog. The practitioner case for frequent intentional compaction. 40-60% context utilization as the target. Includes the BAML case study: 300K LOC Rust codebase, amateur dev, PR approved next morning. Then 35K LOC shipped in 7 hours. Also the leverage cascade: bad research cascades into thousands of bad lines of code.
The six principles: deeper dives
P1 Map, not manual. Anthropic’s Agent Skills documentation. The canonical specification for progressive disclosure architecture. Three-tier loading: metadata at startup, SKILL.md when relevant, reference files on demand. HumanLayer’s “Writing a Good CLAUDE.md” analysis. The API proxy research that revealed Claude Code’s system prompt contains roughly 50 built-in instructions. The empirical basis for the 150-200 instruction ceiling.
P2 Spec before code. GitHub Spec Kit (open-sourced September 2025). The Specify-Plan-Tasks-Implement workflow. Microsoft’s framing: “Once the spec is solid, AI agents become interchangeable.” Osmani, A. (2026). “How to write a good spec for AI agents.” Five principles for agent-readable specifications. Agents as “literal-minded pair programmers.” Huryn, P. (2026). “The Intent Engineering Framework for AI Agents.” productcompass.pm. Agent-design complement to task-spec discipline. Introduces the steering-versus-hard-constraint distinction and the observable-outcomes-not-activities rule that sharpens the Done-when section of the spec template.
P3 Tests as guardrails. Test-Driven Agentic Development (TDAD) paper (March 2026). Targeted test context reduced regressions by 70% on SWE-bench Verified. Generic TDD instructions without targeted context made regressions worse. The evidence that tests must be structured context, not prompt instructions. Willison’s “Red/Green TDD” and “First run the tests” chapters. The practitioner refinements: establish a baseline before changing anything, distinguish between tests the agent broke and tests that were already broken.
P4 Hooks, not instructions. Dotzlaw Consulting (2026). Analysis of prompt-based instruction compliance (70-90%) versus hook-based enforcement (100%). The quantitative case for deterministic guardrails. Anthropic Claude Code Hooks documentation. PreToolUse, PostToolUse, Stop lifecycle hooks. The production specification for hook-based enforcement.
P5 Cross-agent review. Kim, J., Lai, S., Scherrer, N., et al. (2026). “Reasoning Models Generate Societies of Thought.” arXiv:2601.10825. Frontier reasoning models spontaneously simulate multi-agent debates within their chain of thought. Robust reasoning is a social process, even within a single mind. The theoretical foundation for why cross-agent review works. Lu, J., et al. (2024). “Merge, Ensemble, and Cooperate: A Survey on Collaborative Strategies in the Era of LLMs.” The LLM Ensemble literature: combining diverse LLMs consistently outperforms single-model approaches because architectural and training differences produce complementary error patterns.
P6 Failures as harness feedback. Shipper, D. & Klaassen, K. (2025). “Compound Engineering: How Every Codes with Agents.” Every.to. The practice of ending every project with a retrospective that documents what worked for future agent runs. LangSmith Insights Agent documentation. Automated analysis of production traces, failure pattern clustering, root cause surfacing. The operational version of the compound engineering loop.
Pattern catalogs: the scannable view
Ibryam, B. (2026). “12 Agentic Patterns from the Claude Code Leak.” A catalog reference that takes the patterns-book format (problem, pattern, diagram, use-when, trade-off) and applies it to the Claude Code system-prompt exposure. Complementary to the thesis in this article: where the six principles argue for a discipline, Ibryam documents the production mechanisms that instantiate it. Patterns worth noting are Scoped Context Assembly (layered CLAUDE.md loading with import syntax), Tiered Memory with Dream Consolidation (background memory hygiene), named compaction stages (HISTORY_SNIP, Microcompact, CONTEXT_COLLAPSE, Autocompact), Context-Isolated Subagents (context firewalls), and Deterministic Lifecycle Hooks (architecture as enforcement). For readers who want the catalog view alongside the thesis view, read both.
The academic surveys: the view from the field
Wei, T., Zeng, Z., Qiu, R., et al. (2026). “Agentic Reasoning for Large Language Models: Foundations, Evolution, Collaboration.” arXiv:2601.12538. 74-page survey from UIUC, Meta, Amazon, Google DeepMind, and Yale. 800+ references. The formal policy decomposition (π_reason × π_exec) is our equation stated as math. The self-evolving framework formalizes P6. The validator-driven feedback category formalizes P3. The most comprehensive academic synthesis of agentic reasoning available.
Yang, X., Li, L., Zhou, H., et al. (2026). “Toward Efficient Agents: A Survey of Memory, Tool Learning, and Planning.” arXiv:2601.14192. The efficiency-focused companion to Wei et al. Same structural conclusion from a different angle: the harness determines whether agents work efficiently, just as it determines whether they work correctly.
Evans, J., Bratton, B., Agüera y Arcas, B. (2026). “Agentic AI and the Next Intelligence Explosion.” Google Paradigms of Intelligence Team. arXiv:2603.20639. Position paper arguing that intelligence grows like a city, not a single meta-mind. “Put as much effort into building agent institutions as building agents themselves.” The harness is the institution. The organizational framing for why agentic engineering matters beyond individual productivity.
Production evidence: what harness engineering looks like at scale
OpenAI Engineering Blog. (February 2026). “Harness Engineering: Leveraging Codex in an Agent-First World.” Three engineers (later seven), 1.5K pull requests, ~1M lines of code, zero lines written by human hands. The scale proof point for the identity shift.
Anthropic. (2026). “Agentic Coding Trends Report.” Developers use AI in roughly 60% of work but can fully delegate only 0-20% of tasks. The gap is the harness. The empirical case for why harness engineering is the next skill ceiling.
METR. (2025). “Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity.” Sixteen experienced developers, randomly assigned, took 19% longer with AI tools. Predicted 24% faster. The necessary caution: without proper harness engineering, raw AI tools can make experienced developers slower. The harness is what closes the gap.
Classic foundations worth revisiting
Karpathy, A. (2023). “Intro to Large Language Models.” The “LLM as CPU, context window as RAM” framing. The first widely circulated mental model for how to think about LLMs as computational primitives.
Hashimoto, M. (2024-2026). Public writing and talks on harness engineering. Coined the term. “Any time your agent makes a mistake, you take the time to engineer a solution so the agent never makes that mistake again.” The clearest one-sentence statement of P6.
"We are not code writers anymore. We are harness engineers and orchestrators." -- this is a powerful insight.